Did you know that Oracle only joins one table at a time? As Dan Tow puts in his book “SQL Tuning“
[Oracle] simply takes what it’s got at any one point and joins on the next available table to see what happens
or as Jonathan Lewis put it in “Cost-Based Oracle Fundamentals”
Oracle only works on two objects at a time in a join. In fact, you could even argue that the optimizer doesn’t have a long-term strategy for joins, it simply takes what it’s got at any one point and joins on the next available table to see what happens.
For me as someone who reads query plans and VST diagrams, this is a huge relief because it simplifies the concepts for understanding what options Oracle can take with a query. For example, let’s look at this query:
SELECT COUNT (*)
FROM
(SELECT *
FROM a, c, d,g
WHERE
a.planted_date = TO_DATE ('02/10/2008', 'dd/mm/yyyy') AND
a.pears = 'D' AND
a.green_beans = '1' AND
a.planted_date = c.planted_date AND
a.pears = c.pears AND
a.zuchinis = c.zuchinis AND
a.brocoli = c.brocoli AND
a.planted_date = d.planted_date AND
a.pears = d.pears AND
a.harvest_size = d.harvest_size AND
c.oranges = d.oranges AND
c.apples = d.apples AND
(d.lemons = 0 OR d.lemons IS NULL) AND
a.planted_date = g.planted_date AND
a.pears = g.pears AND
a.harvest_size = g.harvest_size AND
c.oranges = g.oranges AND
c.apples = g.apples AND
(g.lemons = 0 OR g.lemons IS NULL) AND
a.zuchinis = '0236'
);Fairly simple, just a lot of joins and filters in the WHERE clause. Let’s look at the VST diagram:

For example, Oracle can’t join (A to D) and then join that result to the results of (C to G). Oracle has to pick ONE object then join in ONE object. That result set gets joined in with ONE object.
The exception to that rule is if there is a non mergable subquery or view. In that case the view or subquery will get evaluated and that result set acts as one Object.
Before we dive into the limitations that only joining one object at a time can have, let’s first look at what happens with this query. By default Oracle chooses this path:

As we can clearly see, this is the wrong path. Why? Because, as previously blogged about, Oracle starts the join on table D who has a non-selective filter returning 0.99 of the table. A more optimized path would be

We start at the table with the most restrictive filter, table A, whose filter returns 0.006 of the table. This path is much better than the first path.
First Path 4.5 secs, 1M logical reads
Second path 1.8 secs 0.2M Logical reads
Let’s look at the extended VST stats on the diagram to confirm our ideas:

Green is Table size
Yellow is Filter Ratio
Red is the Two Table Join Size
It’s clear that the first join should be A to C because it give us the smallest running row count at the beginning of the execution path. (yellow is filter ratio, green is rows in table and red is the resulting join set size between tables including using the filters)
Now let’s look at the query more closely. There is actually a connection from G to D that we can get through transitivity. Here we can see the transitivity (the yellow highlighted fields are the same in D, G and C)

D.apples=C.Apples and C.Apples=G.Apples
same can be said for oranges, so our VST diagram actually looks like:

The transitivity brings to light a lurking ONE-to-ONE relationship between D and G! Thus a join between D and G will return at most min (D,G) rows and maybe less. Let’s see what the row counts are:
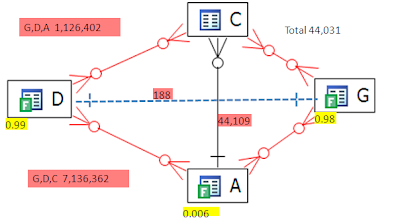
Check it out! the join set between G and D is only 188 rows!!
But if we join G to D, then where do we go? Remember Oracle can only join to one other object, either C or A. Looking at the join set sizes (G,D)C is 7M ! and (G,D)A is 1M ! A big result sets where as the result form A to C is only 44K. How can we take advantage of the low result set from (G to D) and (A to C) at the same time? The answer is to make subqueries that force Oracle to evaluate them separately and then join the results sets:
SELECT COUNT (*)
FROM
( SELECT /*+ NO_MERGE */ c.apples, c.oranges, a.harvest_size
FROM a, c
WHERE
a.planted_date = TO_DATE ('02/10/2008', 'dd/mm/yyyy') AND
a.pears = 'D' AND
a.green_beans = '1' AND
a.planted_date = c.planted_date AND
a.pears = c.pears AND
a.zuchinis = c.zuchinis AND
a.brocoli = c.brocoli AND
a.zuchinis = '0236'
) X,
( SELECT /*+ NO_MERGE */ d.apples, d.oranges, d.harvest_size
FROM d, g
WHERE
d.planted_date = TO_DATE ('02/10/2008', 'dd/mm/yyyy') AND
g.planted_date = TO_DATE ('02/10/2008', 'dd/mm/yyyy') AND
g.apples = d.apples AND
d.oranges = g.oranges AND
d.pears = 'D' AND
g.pears = 'D' AND
g.pears = d.pears AND
g.harvest_size = d.harvest_size AND
(d.lemons = 0 OR d.lemons IS NULL) AND
(g.lemons = 0 OR g.lemons IS NULL)
) Y
WHERE
X.oranges = Y.oranges AND
X.apples = Y.apples AND
X.harvest_size = Y.harvest_size;This final version runs in
elapsed 0.33 secs and 12K logical reads
down from an original
elapsed 4.5 secs and 1M logical reads
Tuning this query manually by an average developer or DBA would take hours., an expert could maybe do it in less than an hour, and a junior analyst might not be able to tune it at all. On the other hand the query can be tuned in minutes with VST diagrams which include join filters, 2 table result set sizes and analysis of transitivity.
The VST relies fitler ratios and 2 table join result set sizes works well. For queries where even the 2 table results take too long, such as a multi day data warehouse query there are other ways to estimate the join result set and filter ratios. We will explore some of these methods in future posts.
Comments